Intro:
Welcome back! In this section of the project, we are going to be building the script to extract data from the internet. Since this is a small-scale application, we can just pull all the data we can get our hands on; however, for larger projects, you might want to be pickier with what you extract.
Initial Breakdown:
The script is going to need to call a web server, extract the data from inside the HTML tags, and store it in a database. Since we’re pulling data directly into the database, we’re going to be developing both simultaneously and I am developing this script inside the database.
Calling a Web Server:
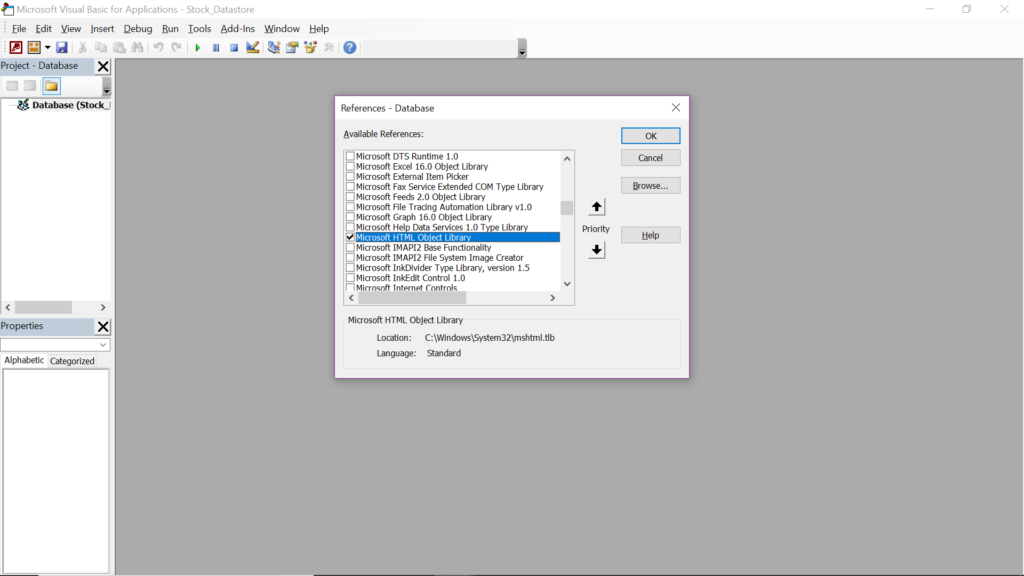
Thankfully, there is a Microsoft-built library for interacting with web servers called “Microsoft HTML Object Library”… go figure.
All we have to do is add the reference to it in our project.
Now, I see this being a class on its own, but we’re going to build it in a module and refactor it later.
Here, I’ve declared my variables — a browser object and an HTML object — and instantiated the browser object. Then, I call the Navigate2 method on the browser object and wait until the response is received. After, we set the HTML object to the document property of the browser.
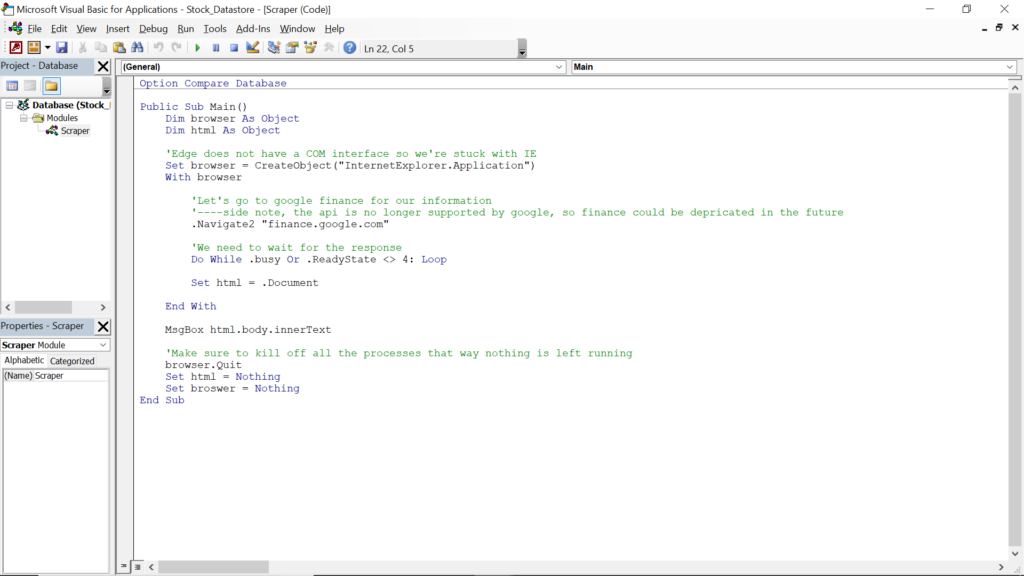
To make sure everything is working, I put in a message box to pop up with text inside the body tag.
Now, what do we do? Well… we’re going to be entering a ticker symbol into the search bar and scraping data from the response. We must first identify the name of the form and search bar to be able to affect it programmatically.
Interacting With HTML:
After searching through the source on the page, I found the identifiers: “f”, and “q”. We can use this by calling the getElementsByName method, because the attribute that has the value of “q” is a name attribute, and see why we get as a response.
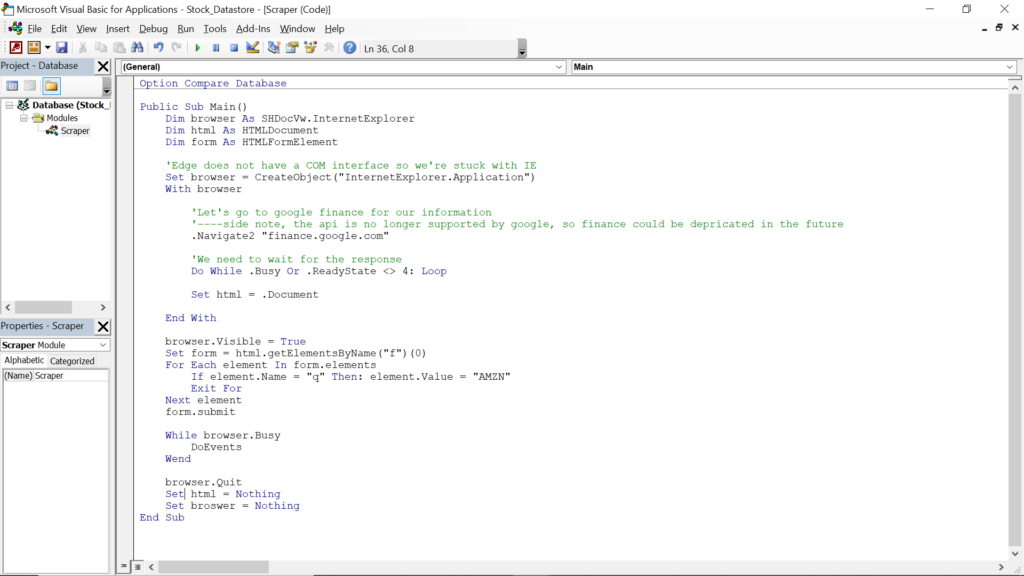
To try and keep things somewhat simple here. I just cycle through the elements of the form and when it reaches the search bar. The script then assigns it a value and submits it.
Any time we make a page load, we want to wait for it to finish. That’s what we’re doing with the while loop.
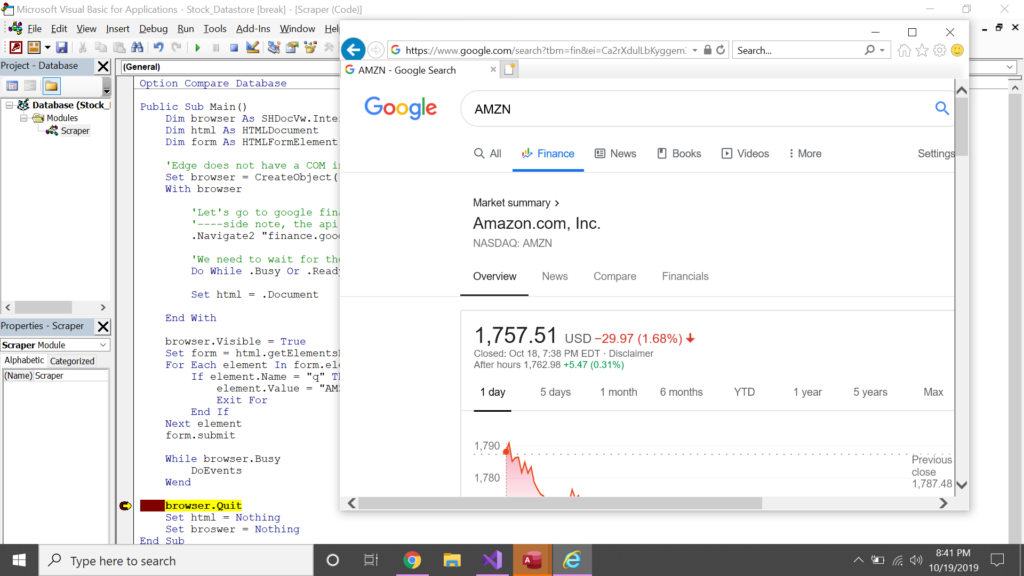
To put in a breakpoint, click right where that red dot is next to the yellow highlighted line. This will stop the code execution at that point.
Refactor for Maintainability and Readability:
After running it, it looks like it’s working. Now we can start scraping data!. But first, let’s refactor.
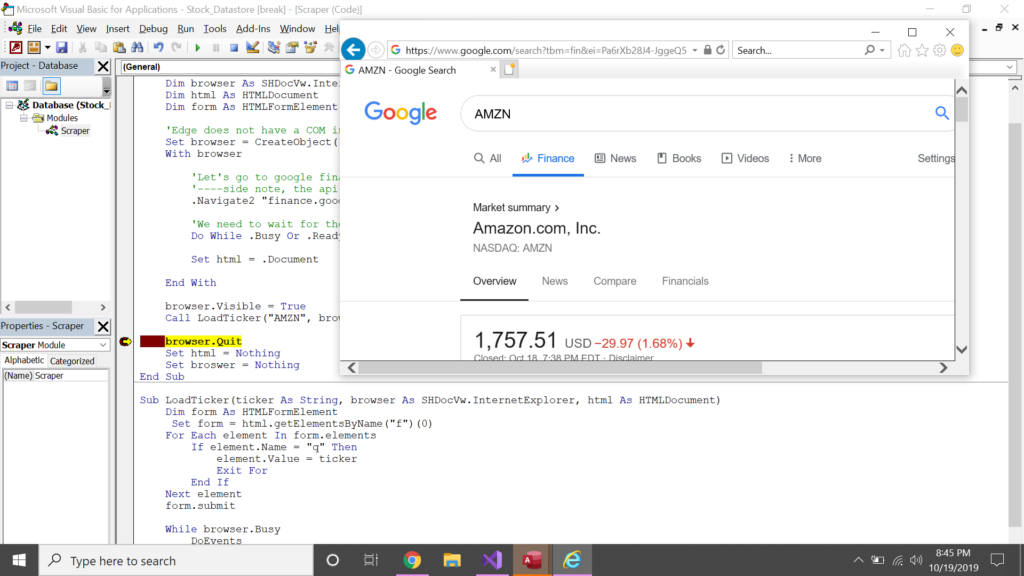
I moved all the logic for filling out the form into a subroutine called “LoadTicker”. I can pass a string as an argument to change what ticker is loaded.
After exploring the HTML more, I found that the data I’m looking for has the really weird class name of “iyjjgb”. So, I just grab all elements with that class name and cycle through them.
This is a good stopping point. Basically, from here, we’re just going to be pulling all that data into the database. Before we can begin doing that, we need to build our data model and implement the tables. Click to the next article to find out how!
Footnote:
Thank you for taking the time to read the article. If you enjoy these, leave a comment. If you notice anything incorrect or could be explained better, leave some feedback! If you would like to contact me about what I can do to help your company, please click the “Contact Me” tab from the navigation and I should get back to you within a couple of business days.